C++11 Multi-threaded Programming: Task-Queue Patterns - Part 1
Introduction
In multi-threaded programming paradigm, a task-queue is widely used pattern for inter thread communication.
Process is the method where the processing of the work item happens. This is called by consumer thread after it has dequeued the WorkItem.
1. Single Producer and Single Consumer

We begin with a single producer and consumer pattern. Since we have a single consumer thread processing our tasks, all the tasks gets executed sequentially in the order of their insertion in the queue.
DoWork gets executed in the context of our consumer thread. This thread dequeues the WorkItem and calls its Process. In our SleepyWorkItem case, the thread just sleeps for some duration.
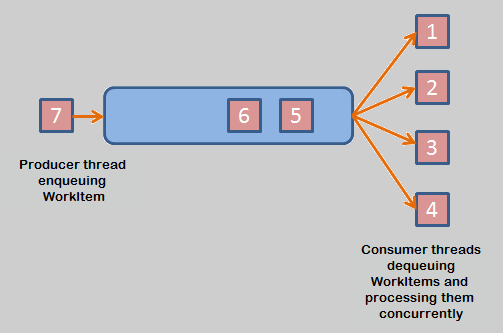
2. Single Producer and Multiple Consumers - Unordered Delivery
Id 1, 100 millisec is ready for delivery!
Id 2, 700 millisec is ready for delivery!
Id 3, 500 millisec is ready for delivery!
Id 4, 200 millisec is ready for delivery!
Id 5, 300 millisec is ready for delivery!
Completed work items in 700 milliseconds.
We see that we have got the same throughput as pattern 2 and also have maintained the delivery order of our work items as pattern 1.
More Thoughts
The above implementations used WorkItemPtr to refer to our work item instance. An alternate implementation can use a template argument implementing Process and Ready methods. The value returned by std::thread::hardware_concurrency can be used as a hint to configure number of consumer threads.
In the next post, we will see how to realize these patterns using std::async C++11 feature.
Please feel free to leave your feedback and thanks for reading!
In multi-threaded programming paradigm, a task-queue is widely used pattern for inter thread communication.
A task is a CPU or IO bound work item that completes in finite time. A queue is a container that holds these tasks and facilitates first-in-first-out (FIFO) order of their execution. This queue acts as a bridge between producer and consumer threads and logically separates their processing logic. It introduces an asynchronous flow in the execution wherein the producer thread delegates the processing of work item to another thread and goes back to the processing of newer work items.
A task is inserted in the queue by a producer thread and consumer thread removes the task from the queue for further processing. A common example of this flow is a thread that reads a raw buffer from network socket, enqueues the buffer and goes back to listening mode. The enqueued buffer is dequeued and processed by another thread. This thread may run the application logic or may enqueue the processed buffer in another task-queue for next level of processing.
There can be multiple producer/consumer threads performing these enqueue and dequeue operations on the same queue.
This article discusses three task-queue patterns.
- Single Producer and Single Consumer
- Single Producer and Multiple Consumers - Unordered Delivery
- Single Producer and Multiple Consumers - Ordered Delivery
For simplicity, all these patterns have a single producer with no maximum queue size limit. The WorkItem represents task that needs processing and consumers represents worker threads that process these WorkItems.
The code base can be downloaded from GitHub.
The article uses C++11 introduced thread synchronization primitives for illustration and assumes that the reader is familiar with them.
The code base can be downloaded from GitHub.
The article uses C++11 introduced thread synchronization primitives for illustration and assumes that the reader is familiar with them.
We start by defining our WorkItem abstract class.
class WorkItem {
public:
WorkItem() = default;
virtual ~WorkItem() = default;
virtual void Process() = 0;
};
typedef std::shared_ptr<WorkItem> WorkItemPtr;
class SleepyWorkItem: public WorkItem {
public:
SleepyWorkItem(uint32_t id, uint32_t msec_duration):
id_(id), msec_duration_(msec_duration) {}
~SleepyWorkItem() = default;
void Process() override {
std::this_thread::sleep_for(std::chrono::milliseconds(msec_duration_));
}
uint32_t id() const {
return id_;
}
uint32_t msec_duration() const {
return msec_duration_;
}
private:
uint32_t id_;
uint32_t msec_duration_;
};
SleepyWorkItem is our class that implements the Process method. The calling thread sleeps for some duration in this method. Our task or work item queue holds smart pointers (WorkItemPtr) to the SleepyWorkItem instances.

We begin with a single producer and consumer pattern. Since we have a single consumer thread processing our tasks, all the tasks gets executed sequentially in the order of their insertion in the queue.
class Worker {
public:
typedef std::function AppCallback;
Worker(const AppCallback& callback);
~Worker();
void Add(WorkItemPtr work_item);
private:
void DoWork();
const AppCallback callback_;
std::queue<WorkItemPtr> queue_;
std::thread thread_;
std::mutex mutex_;
std::condition_variable cond_;
bool finished_;
};
// Implementation
Worker::Worker(const AppCallback& callback):
callback_(callback), thread_(&Worker::DoWork, this), finished_(false) {
}
Worker::~Worker() {
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
finished_ = true;
}
cond_.notify_one();
thread_.join();
}
// Producer thread context
void Worker::Add(WorkItemPtr work_item) {
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
queue_.emplace(work_item);
}
cond_.notify_one();
}
// Consumer thread context
void Worker::DoWork() {
while (true) {
WorkItemPtr work_item;
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
cond_.wait(lock, [this] () {
return !queue_.empty() || finished_;
});
if (!queue_.empty()) {
work_item = std::move(queue_.front());
queue_.pop();
} else if (finished_) {
break;
}
}
if (work_item) {
work_item->Process();
callback_(work_item);
}
}
}
Lets enqueue following five work items and register ReadyForDelivery as our application hook.
void ReadyForDelivery(WorkItemPtr work_item) {
std::shared_ptr<SleepyWorkItem> sleepy_work_item =
std::dynamic_pointer_cast<SleepyWorkItem> (work_item);
std::cout << "Id " << sleepy_work_item->id() << ", " <<
sleepy_work_item->msec_duration() <<
" millisec is ready for delivery!" << std::endl;
}
int main(int argc, char** argv) {
std::vector<WorkItemPtr> items;
items.emplace_back(std::make_shared<SleepyWorkItem>(1, 100));
items.emplace_back(std::make_shared<SleepyWorkItem>(2, 700));
items.emplace_back(std::make_shared<SleepyWorkItem>(3, 500));
items.emplace_back(std::make_shared<SleepyWorkItem>(4, 200));
items.emplace_back(std::make_shared<SleepyWorkItem>(5, 300));
auto start = std::chrono::high_resolution_clock::now();
{
Worker worker(std::bind(&ReadyForDelivery, std::placeholders::_1));
for (WorkItemPtr item: items) {
worker.Add(item);
}
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << "Completed work items in " <<
std::chrono::duration_cast(end - start).count() << " milliseconds." << std::endl;
return 0;
}
Id 1, 100 millisec is ready for delivery!
Id 2, 700 millisec is ready for delivery!
Id 3, 500 millisec is ready for delivery!
Id 4, 200 millisec is ready for delivery!
Id 5, 300 millisec is ready for delivery!
Completed work items in 1800 milliseconds.
As expected, the consumer thread sequentially processed our tasks and it took accumulation of all the task's Process duration to finish.

We can increase our throughput of processing work items by having a pool of consumer threads. If one consumer thread is busy executing a work item, other consumer threads can concurrently process newly enqueued work items. Compared to our previous pattern, the only change would be that now we have a list of consumer threads.
3. Single Producer and Multiple Consumers - Ordered Delivery

This pattern exploits the best of aforementioned two patterns. It maintains the order of delivery and also executes our work items concurrently. It enhances pattern 2 by introducing a delivery queue and a delivery thread. The work item is enqueued by producer thread into two queues instead of one. The delivery queue is for maintaining the order (FIFO) and the work item is dequeued by delivery thread only when the head of the queue is ready.
Since ReadyForDelivery is called only by delivery thread, the application should perform light weighted processing in this handler else the delivery thread shall become the bottleneck.
class WorkerPool {
public:
typedef std::function<void (WorkItemPtr)> AppCallback;
WorkerPool(const AppCallback& callback, uint32_t pool_size);
~WorkerPool();
void Add(WorkItemPtr work_item);
private:
void DoWork();
const AppCallback callback_;
std::queue<WorkItemPtr> queue_;
std::vector<std::thread> threads_;
std::mutex mutex_;
std::condition_variable cond_;
bool finished_;
};
// Implementation
WorkerPool::WorkerPool(const AppCallback& callback, uint32_t pool_size):
callback_(callback), finished_(false) {
for (uint32_t i = 0; i < pool_size; ++i) {
threads_.emplace_back(&WorkerPool::DoWork, this);
}
}
WorkerPool::~WorkerPool() {
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
finished_ = true;
}
cond_.notify_all();
for (std::thread& thread: threads_) {
thread.join();
}
}
// Producer thread context
void WorkerPool::Add(WorkItemPtr work_item) {
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
queue_.emplace(work_item);
}
cond_.notify_all();
}
// Consumer threads context
void WorkerPool::DoWork() {
while (true) {
WorkItemPtr work_item;
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
cond_.wait(lock, [this] () {
return !queue_.empty() || finished_;
});
if (!queue_.empty()) {
work_item = std::move(queue_.front());
queue_.pop();
} else if (finished_) {
break;
}
}
if (work_item) {
work_item->Process();
callback_(work_item);
}
}
}
Lets create WorkerPool of 4 threads and enqueue same work items.
... WorkerPool worker_pool(std::bind(&ReadyForDelivery, std::placeholders::_1), 4); ...
Id 1, 100 millisec is ready for delivery!
Id 4, 200 millisec is ready for delivery!
Id 5, 300 millisec is ready for delivery!
Id 3, 500 millisec is ready for delivery!
Id 2, 700 millisec is ready for delivery!
Completed work items in 700 milliseconds.
We see that the our processing time has reduced from 1800 to 700 milliseconds. The 700 milliseconds represents the duration of work item (Id=2) that takes the maximum time to complete. When this is being processed, other consumer threads completed the remaining work items concurrently.
We also observe that we have lost the delivery order of the work items. It seems that the shortest work item is getting completed first. This pattern should only be used if the ordering (FIFO) is not desired in the delivery of work items.
Furthermore, the ReadyForDelivery function needs to be thread safe as multiple worker threads are calling it concurrently once they are done processing their work items.
Furthermore, the ReadyForDelivery function needs to be thread safe as multiple worker threads are calling it concurrently once they are done processing their work items.

Furthermore, we also enhance our WorkItem and SleepyWorkItem classes to indicated if work item is ready to be delivered.
A new interface method Ready has been declared.
class WorkItem {
public:
WorkItem() = default;
virtual ~WorkItem() = default;
virtual void Process() = 0;
virtual bool Ready() const = 0;
};
typedef std::shared_ptr<WorkItem> WorkItemPtr;
Our new SleepyWorkItem now implements the Ready method. This method returns true if SleepyWorkItem processing is complete.
class SleepyWorkItem: public WorkItem {
public:
SleepyWorkItem(uint32_t id, uint32_t msec_duration):
id_(id), msec_duration_(msec_duration), ready_(false) {}
~SleepyWorkItem() = default;
void Process() override {
std::this_thread::sleep_for(std::chrono::milliseconds(msec_duration_));
ready_.store(true);
}
bool Ready() const override {
return ready_.load();
}
uint32_t id() const {
return id_;
}
uint32_t msec_duration() const {
return msec_duration_;
}
private:
uint32_t id_;
uint32_t msec_duration_;
std::atomic<bool> ready_;
};
Lets go over the implementation.
class OrderedWorkerPool {
public:
typedef std::function<void (WorkItemPtr)> AppCallback;
OrderedWorkerPool(const AppCallback& callback, uint32_t pool_size);
~OrderedWorkerPool();
void Add(WorkItemPtr work_item);
private:
void DoWork();
void DoDelivery();
void ReadyForDelivery(WorkItemPtr work_item);
const AppCallback callback_;
// Consumer threads and their queue
std::queue<WorkItemPtr> queue_;
std::vector<std::thread> threads_;
std::mutex mutex_;
std::condition_variable cond_;
bool finished_;
// Delivery thread and its queue
std::thread delivery_thread_;
std::queue<WorkItemPtr> delivery_queue_;
std::mutex delivery_mutex_;
std::condition_variable delivery_cond_;
bool delivery_finished_;
};
// Implementation
OrderedWorkerPool::OrderedWorkerPool(const AppCallback& callback, uint32_t pool_size):
callback_(callback), finished_(false), delivery_thread_(&OrderedWorkerPool::DoDelivery, this),
delivery_finished_(false) {
for (uint32_t i = 0; i < pool_size; ++i) {
threads_.emplace_back(&OrderedWorkerPool::DoWork, this);
}
}
OrderedWorkerPool::~OrderedWorkerPool() {
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
finished_ = true;
}
cond_.notify_all();
for (std::thread& thread: threads_) {
thread.join();
}
{ // Lock scope
std::unique_lock<std::mutex> lock(delivery_mutex_);
if (delivery_queue_.empty()) {
delivery_finished_ = true;
}
}
delivery_cond_.notify_one();
delivery_thread_.join();
}
// Producer thread context
void OrderedWorkerPool::Add(WorkItemPtr work_item) {
{ // Lock scope
std::unique_lock<std::mutex> delivery_lock(delivery_mutex_);
delivery_queue_.emplace(work_item);
}
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
queue_.emplace(work_item);
}
cond_.notify_all();
}
void OrderedWorkerPool::DoWork() {
while (true) {
WorkItemPtr work_item;
{ // Lock scope
std::unique_lock<std::mutex> lock(mutex_);
cond_.wait(lock, [this] () { return !queue_.empty() || finished_; });
if (!queue_.empty()) {
work_item = std::move(queue_.front());
queue_.pop();
} else if (finished_) {
break;
}
}
if (work_item) {
work_item->Process();
delivery_cond_.notify_one();
}
}
}
void OrderedWorkerPool::DoDelivery() {
while (true) {
WorkItemPtr work_item;
{ // lock scope
std::unique_lock<std::mutex> delivery_lock(delivery_mutex_);
delivery_cond_.wait(delivery_lock, [this] () {
return (!delivery_queue_.empty() && delivery_queue_.front()->Ready()) || delivery_finished_;
});
// If head of the delivery queue is ready, remove it for delivery
if ((!delivery_queue_.empty() && delivery_queue_.front()->Ready())) {
work_item = std::move(delivery_queue_.front());
delivery_queue_.pop();
if (delivery_queue_.empty() && finished_) {
delivery_finished_ = true;
}
} else {
// We are done with all the work items and finalize has been called,
// exit the thread loop
if (delivery_queue_.empty() && delivery_finished_) {
break;
}
}
}
if (work_item) {
callback_(work_item);
}
}
}
This implementation has some complexity compared to previous examples. Our consumer thread notifies the delivery thread once it has completed the processing of work item. The delivery thread dequeues its head work item only if the work item is ready. It may happen that other work items may get ready before the head of the delivery queue. The delivery thread will wait for them in which case.
Since ReadyForDelivery is called only by delivery thread, the application should perform light weighted processing in this handler else the delivery thread shall become the bottleneck.
Lets create OrderedWorkerPool of 4 threads and enqueue same work items.
... OrderedWorkerPool worker_pool(std::bind(&ReadyForDelivery, std::placeholders::_1), 4); ...
Id 1, 100 millisec is ready for delivery!
Id 2, 700 millisec is ready for delivery!
Id 3, 500 millisec is ready for delivery!
Id 4, 200 millisec is ready for delivery!
Id 5, 300 millisec is ready for delivery!
Completed work items in 700 milliseconds.
We see that we have got the same throughput as pattern 2 and also have maintained the delivery order of our work items as pattern 1.
The above implementations used WorkItemPtr to refer to our work item instance. An alternate implementation can use a template argument implementing Process and Ready methods. The value returned by std::thread::hardware_concurrency can be used as a hint to configure number of consumer threads.
In the next post, we will see how to realize these patterns using std::async C++11 feature.
Please feel free to leave your feedback and thanks for reading!

Liked it, I would love to see your views on Composable futures, they are the -future- paradigm for all IO processing and concurrent programming.
ReplyDeleteThanks Amritanshu. Would like to cover Composable features along with go lang's support in separate article.
DeleteThis comment has been removed by the author.
ReplyDeleteFANTASTIC, easy to understand and practical. Expecting to learn more such practical things which are of use in c++ programmers day to day life
ReplyDelete